
So many decisions???????
Software systems come in all shapes and sizes, but in the modern world, the online Software-as-a-Service model is common. The typical system comprises five main parts:
- UI – for the user to interact – typically using a browser or mobile app, and maybe an API.
- Front-end – supports Internet/Intranet access to your users.
- Services – the code and storage that execute your function. This further decomposes into
- Compute – the processing
- Storage – of the data
- Services – the code that glues all this together (typically COTS).
- Backend – supports outgoing requests to other systems, such as a payments provider, inventory manager, or fulfilment system.
This article shows the decisions you need to make for a new SaaS product and nudges you toward their solution. I’m calling the product GizmoWorld, and the purpose of the product is for the user to make and share Gizmos. Let’s start with the important concept of phasing – what is OK to defer and what is not.
Phasing and future-proofing

An early mentor gave me this sage advice:
The role of an architect is not to solve the problems of the future, but to allow the architects of the future to solve their problems with the technology of the future.
This extends the YAGNI principle with a precautionary note to make your system extensible. Today YAGNI is a cornerstone of modern architecture, as we recognize that refactoring is (usually) cheaper than build-in-advance. That’s not the case for some foundational architecture choices – for example, you don’t want to migrate through three database technologies in your first year – each of which was good enough for the time. In your first year or two – I will call this Early Adopter phase – you want to be madly building out features, not retrofitting a poor day-one decision. Some poor choices will put multi-month-long holes in your schedule:
- migrating your stored data to a new technology or new location.
- migrating your UIs to a new technology (UI technologies interwork poorly)
- retro-fitting security to a system with deep security flaws
- changing programming languages
and these will punch multi-week holes:
- adding distributed processing to a single-site system
- adding Internationalization to a system that previously spoke English only
- changing external APIs, internal APIs and internal data flow
- splitting a monolithic system into microservices.
Above all, there are some errors so bad they will kill or maim your product in its first year. You cannot defer on them at all –
- a half-hour outage during peak times
- loss of data (say for more than one per cent of users for more than one day)
- security breach involving PII loss.
You need to read Crossing the Chasm. Your goal in your first couple of years is to get out of Early Adopter phase. So consider the things in this section to be guard rails – rush to market as fast as you can with adequately bug-free code with great UX, but not so fast that one of these bites you badly.
This looks like a pretty amorphous bunch of things, but “The decisions you wish you could get right early in the project” is Martin Fowler’s definition of software architecture. So now I will move on to another early phase killer – exotic tech.
Tech radar 

Let’s face it – your system does not have unique hosting needs – especially in its Early Adopter phase. Yeah, Facebook builds custom data centres, AWS designs custom CPUs, and Google invented BigTable. But not in their first couple of years – instead, they all strongly focused on customer-visible value – the feature code and User experience. So here are three rules for new products:
- Don’t use exotic tech – use tech that has been mainstream for a few years – Stack Overflow has lots of answered questions, and your team has experience.
- Don’t stress the hosting – if your design needs 10K DB writes per second or a billion rows in an RDBMS, do a different design.
- Don’t invent infrastructure – it’s good fun to build a distributed cache or a storage engine, but wait till you are in the Early Majority phase (it might be OTS by then).
Even in established technologies, don’t prematurely optimise.
- Do you really need containers, or will a JAR on a VM do?
- Do you need microservices, or will a monolithic app of 50KLOC do?
- Do you need event streams, or is LPC or RPC OK?
- Do you need to process through multi-AZ failures in one region?
Every time you introduce a new technology, you divert effort, expose yourself to defects, and introduce operational complexity. Sometimes you need to do that – if your product realistically generates 10 billion records per year, don’t try to force it into an RDBMS. You will need Cassandra or Dynamo from day one.
Be extremely wary about building new infrastructure technology. On the other hand, be generous with inventing feature technology – that is your value add that will generate revenue. Be very generous in building a good UX – today, it has to look polished to get eyeballs.
So what is a mainstream tech stack in 2023 (in the non-Microsoft world)? This will differ if you have built up another skill set, but a reasonable stab at it is:
| Space | Product | Applicability | Contraindications | Notes |
| Storage | MySQL (maybe PostgreSQL) | Default choice | More than 100M rows -> Cassandra, Dynamo Multi-region updates -> Cassandra, Dynamo Ad-hoc queries -> Elastic, AWS OpenSearch, Mongo |
These are default through familiarity, reliability and support. They are essentially single-region solutions. |
| Cassandra, Dynamo | Multi-billion rows Updates from multiple regions |
Less than a billion rows -> MySql Ad-hoc queries -> Elastic, Mongo |
These tackle the CAP theorem head-on but require more skill to code. | |
| Mongo, Elastic | Ad-hoc searching | ACID transaction -> MySQL | Support arbitrary queries across semi-structured data. | |
| Server language | Kotlin | Default choice | If your backend is very thin -> Node, Python | Less code and defects than Java, but 100% compatible. |
| Java | Yesterday’s choice | Not for new projects -> Kotlin | No aspect is better than Kotlin. | |
| Node (TypeScript), Python | Simple back ends that intend to stay simple. | Complex backends -> Kotlin | Interpreted languages slightly reduce CD/CI chain complexity. | |
| Server frameworks | None | Default choice | Existing Spring Boot tools chain -> Spring Boot | Native APIs for web servers, databases, and messaging, are now simple to use. |
| Spring Boot | Limited | Greenfield -> None | Spring patched many language and API holes in early Java. In 2023, these have diminished, so Spring (Boot) is no longer worth the overhead. | |
| Web interface | Jetty | Default choice | Thousands of concurrent requests per process -> KTOR and Coroutines | Creates a thread per processing request, which hits scale limits in the 1000’s. |
| KTOR | Limited | Low concurrent requests -> Jetty. | KTOR and coroutines are somewhat immature. | |
| Memory cache | Hazelcast | Default choice | Better than Redis or Memcached. It’s simple to manage. | |
| Message queue | Kafka / Kenesis | Default choice | RabbitMQ / SQS could be useful for low-end. | |
| Packaging/Orchestration | JAR + cloud autoscaler | Default choice | Lots of small services -> Docker and Kubernetes Not 12-factor app -> Docker + Kubernetes |
Deploying a JAR to a VM is the simplest CD/CI model, and using the cloud autoscaler is the simplest orchestrator. It wastes resources if JAR needs less than a micro VM. |
| Docker+Kubetnetes | Many small services or non-12 factor apps | Few services -> JAR | Needed for large-scale micro-services with many small services – pods are smaller than VMs. | |
| Compute | VM | Default choice | Low loads -> Serverless | Serveless (eg AWS Lambda or FarGate) can give better resource utilization – especially for low loads. They are slightly harder to build and test for developers. |
| Serverless | Simple functions executed at low rates. | Has inter-request state -> VM Consistent high load -> VM |
||
| UIs | REACT | The default for complex UIs | Simple UIs – Vue | You don’t want to be learning REACT on a new project. |
| Vue | The default for simpler UIs and startups | Best fresh-start choice | ||
| Load balancer, WAF, CDN, DNS | Cloud vendor | Always | Cloud vendors get this right and easy to manage. |
Now we have the guard rails in place, we can start digging into Gizmo World, and the first conversation with our product owner:
Product owner questions 

This is an interaction, as product owners often don’t know the answers either. A useful approach is talking about the business plan/case for the product – after all, someone will have ticked off the expenditure, and they will have some expectations. If you ask, “How many GB of storage do you need?” the PO will justifiably have a blank face. Instead, ask commercial questions like:
- What are the competing/overlapping products? (You need to get familiar with them)
- What is our differentiator? Or is it a me-too?
- How do we make revenue? Per user? Per gizmo? Click advertising?
- What are our year two revenue numbers?
- How many gizmos will an active user generate per month?
- Do customers regard this as a business-critical system?
- When will the system need to be multilingual?
- What are our data sovereignty issues?
- Are there statutory constraints?
- How do we bill?
You can prompt a bit of this with some basic numbers that apply pretty universally for a new product:
- You need ten people to cover the roles – analysis, development, operations, sales, management, help desk etc. That’s an annual payroll of around $2M.
- Most products can only charge between $10 to $100 per user per year, so you will have between 20k and 200k users.
- In the modern world, offering the product for free for a period, or some usage limit, means that you will have many more users, say 200k to 2M accounts.
- To generate that revenue from Google AdSense, you would need 100M page views per month – that’s over 10M users and unicorn territory.
- You can probably go live with 20KLOC for your basic function but would have to grow to 50KLOC the next year (30kLOC is comfortable for one dev team for a year on a green-fields project)
So based on this, you can:
- dimension your storage and external operation rate
- see if you are in the 4x9s or 5x9s regime
- understand if you need exotic technology in the UI or backend.
I think that in 2023, its safe to assume that:
- You will store PII, and you have to protect it – at rest, on your private network, on the internet, in the browser/web app.
- You will comply with GDPR.
- The baseline availability is 4x9s (i.e. 5 minutes downtime per month), with the longest outage being 10 minutes.
- Less than one-minute data loss (in the face of any catastrophe).
- At some stage, on-soil storage will be required to enter certain markets.
Microservices and multi-process
Monolithic systems are faster and easier to operate than micro-services – there is no inter-process communications overhead and only one thing to test and deploy. Single-process monolithic systems (vertical scale) are faster and easier to build than systems designed to run on horizontally scaled processes – you can use program language caches, semaphores and such. So why don’t we build vertically scaled monolithic systems that much any more?
One large system killer is entanglement:
- code – one change has unexpected and far-reaching consequences in spaghetti
- storage – uncontrolled access to the database, making it impossible to change the storage model without mass code rewrites
- social – when one team wants to change something, they have to coordinate changes with multiple other teams
- build – the time to compile, test and debug the system goes up at about LOC2 – for large systems, the regression test suite can take hours to run and days to remove a defect.
The other killer is vertical scale – say one CPU can process ten transactions per second, large AWS instances (64 CPUs and 1TB of memory) will process 640 TPS, and the largest (448 CPUs and 18TB of memory) might do 4000 TPS. That $2.6M per year for two AZs – and for typical peaky loads most of the time, those CPUS will be doing nothing – except generating greenhouse gasses and consuming your money. And what if you need 10Ktps for your peak days?
Microservices are a way of imposing strong boundaries to mitigate entanglement. It prevents uncontrolled code-level calls between services, and one service’s credentials won’t allow DB access to another service’s tables. Horizontal scale is the approach to effectively limitless throughput, with cost proportional to load. So if GizoWorld is challenging Google or Twitter, these things matter a lot. Most of us don’t do that – during your first year, is your peak TPS only 100? Will you have only two dev teams – say a UI and back-end team? If so, then a single-process monolithic structure is probably the best approach to getting your code fast to market. If you can go live with 20-50KLOC, you could defer your micro-servicing decision to your post-revenue phase.
So for this discussion, I will assume that you will need a multi-process and microservice design. When is your choice – you are the boiled frog.
The shape of the solution
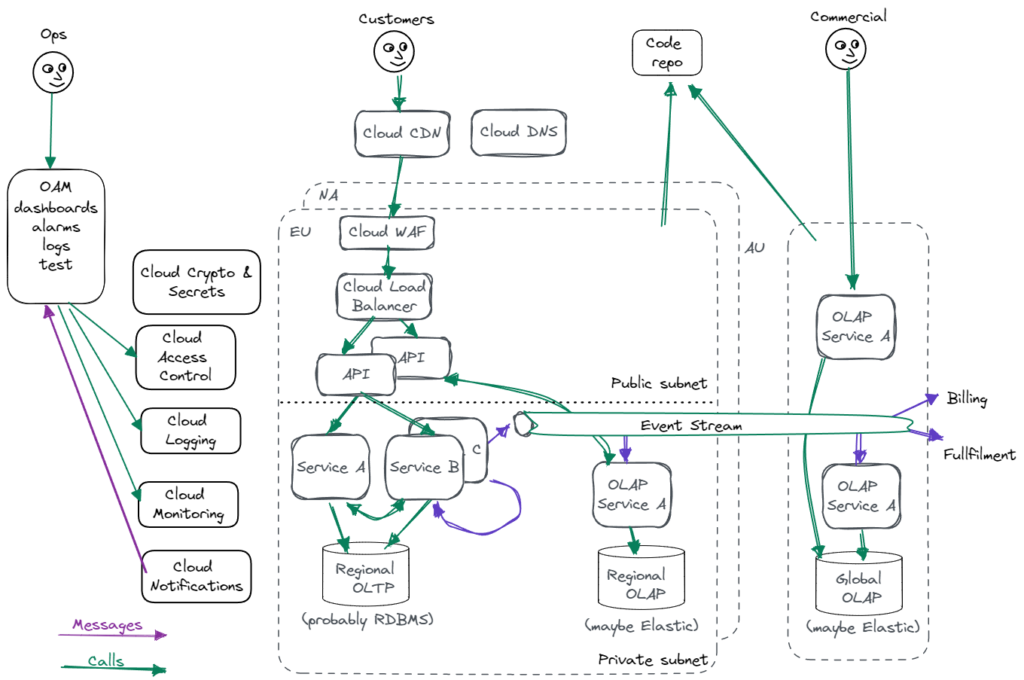
The typical SaaS structure looks like this – obviously, there are variants, and services are specific to your project, but this gives us a basis for discussion.
Choosing storage technology

Pace layering is the core tool an architect has to allow a system to be evolved by future architects. At the bottom layer, as the “systems of record”
is where data is stored. This section looks at the questions that guide your storage technology. As we saw above, you need to plan this with a 2+ year horizon.
| Decision | Typical design responses |
| Do you need an OLTP and an OLAP store? | Typically today, the answer is yes, as no tech is good at both rapid transactional response and sophisticated search/reporting. Having an OLTP and OLAP store lets you pick good tech in each space (eg RDBMS and Elastic), and you can also design your OLAP to protect Personal Identifying Information. It’s a good match for a CQRS approach. |
| Do you have data sovereignty constraints? | Typically today, the answer for International products is ‘yes’ if you sell to corporates, particularly for PII. You can usually get by with de-identified data in a global location for your analytics. So you might end up with three tiers of storage – OLTP and OLAP in-region, and global OLAP. |
| What is your retention policy, and how will you destroy data? | You must destroy highly sensitive data as soon as it is no longer needed – otherwise, you are building up a liability for no benefit. For highly sensitive data (driver’s license, SSN etc), your retention period might be hours. Remember, you don’t need to store a Passport Number to prove that you have collected one – an HMAC does that and carries no risk. |
| What is your replication strategy? | You need close-to-realtime replication to another AZ. This ensures against AZ failure. |
| What is your offline backup restore strategy? | Offline periodic backup covers malware or broken code trampling on your data. The backup period is your advertised RPO. Cloud tech lets this drop to 5 minutes. If your DB is trashed by malware, your actual recovery point is the time to recognize the trashing. |
| How will you keep PII protected at rest? | You do application-level encryption of PII. Nothing else is good enough, see Personal data safe at rest. |
| Do you need to support cross-regional storage? | Probably not. If you do, cross-regional replicate the backups (it’s easy on a cloud). |
| What is the record count – for each store? | Try to keep your OLTP less than one billion. |
| How will you manage and update schemas? | Use Fluid Schemas. Write the data with a version number and uplift to the current version on read in your code (blog article coming on this). |
| What are the transactionality constraints? | Your OLTP probably needs ACID, which is sort-of-free in an RDBMS. BASE is usually OF for OLAP. |
| What are your reporting/analytics requirements? | Report off the OLAP – pick a tech with a reporting tool attached (e.g. Elastic/Kibana). |
| Are there corporate Data Lake/Warehouse needs? | If you have a corporate data lake/warehouse, push your data to it (probably via Kafka). Don’t let any other system read your DB. |
| What is the data read/write rate? | Less than 2000 per second is comfortable for RDBMS. |
On top of that stuff where you have a choice, these are ‘just do it items’:
| Just do it / don’t do it. | Why |
| Cloud DB management. | You are not special – use your cloud vendor’s managed storage (AWS has 15+ options), and all the operational tooling. |
| DB access | No humans have DB WRITE access. If a human has DB READ access, that data will end up on the black market. |
| DB Scripts and DDL | Don’t have any – they break your CD/CI process – write code instead. Use code for the DDL with Liquibase. |
| Normalization | Typically aim for a key-value store, where each table is a major business concept owned by one service. The value will be the JSON encoded attributed related to the key (including list attributes). Add secondary indexes for other data where required for performance. Avoid joins. |
| ORM | Don’t. The object abstractions are so leaky in function and performance that you need strong SQL skill anyway. In the de-normalized key-value model typical for micro-services, they provide little value. |
| TDE | Don’t bother. Adds nothing to security. See Personal Data Safe at Rest |
Processing 

Now your storage model is defined, we move the processing layer.
| Decision | Typical design response |
| How to modularize code? | Microservices, deployed as JAR, executed on a VM. For 12-factor apps (the Java goal), containers are a micro-optimization. |
| How to delegate between services? | Choreography. Blocking calls for functions required to be returned in the request. Messages for asynchronous calls. |
| How to locating services and call them? | If you’re into containers on day 1 – you need Istio or Linkerd. Otherwise, Consul and app-level encrypted HTTP. |
| How to send messages (pub.sub)? | Kafka (with app-level encryption). |
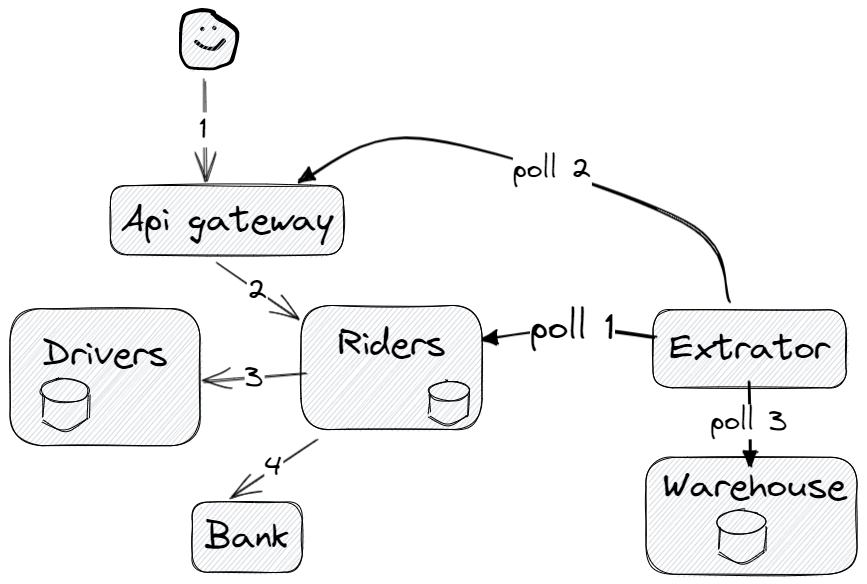
| How to transfer data to OLAP. | With microservices, no service has the full data model. The data has to be extracted through the API, and Data extraction from microservices shows a couple of approaches. |
| How to do period tasks with execute-once semantics? | Cloud scheduler (eg AWS SNS) |
| How to do ephemeral storage? | Hazelcast |
| Cross-process locking / leader election? | Hazelcast |
| How to encrypt? | Symmetric AES-GCM with the key from cloud crypto service either from cloud secret manager (faster, cheaper, less secure). |
| How to store passwords? | Cloud secrets manager (with password rolling). |
| Do you need a front-end layer? | Typically yes – to manage authentication and authorization, flow control, failover, and provide Content Disarm and Reconstruction. |
| Process orchestration | Kubernetes or your cloud auto-scaler. (Even if you are building a singleton process – this will give you failover resilience for free). |
| 12 Factor App | Why not? They will simplify your CD/CI and give more run-where options. |
Now we move to data ingress and egress.
Network 

You will want to use all your cloud vendor’s tools to build your front-end data ingress and egress. This is stuff that is hard to get right and needs ongoing maintenance. Your cloud vendor will provide integrated tooling for these functions and will operate them as managed services.
| Decision | Typical design response |
| What subnets? | Create a 10.0.0.0/8 VPN address range, with eight subnets in each AZ and 32 AZs. This gives each subnet a /16 CiDR (64k addresses). Ensure you don’t overlap with any other cloud or on-prem ranges (to allow transits). Use NAT to route outgoing IPV4 requests. |
| What load balancer? | Use the cloud Level 7 load balancer (eg AWS ALB), with liveness checking and auto-restart. This will terminate the TLS (1.2+), and reestablish HTTPS to your apps. Use the cloud vendor to manage the key pairs. |
| Protecting the front end? | User the cloud WAF to limit rates to reasonable values – particularly to authentication APIs. |
| CDN? | Use the cloud CDN if there is a long distance between your customers and the service or if the Internet is weak in your target markets. |
| DNS | From cloud vendor – integrates to load balancer. |
| HTTP Egress | If you do outbound HTTP, you need a controlled egress point to prevent malware data exfiltration. A NAT gateway security bound to a dedicated VM is a start. If you can, bind this to specific IP addresses (e.g. payment provider). |
| Email and SMS egress | Outbound emails must only be sent with consent, and that consent can be withdrawn. Your cloud vendor will have a solution. SMS is more controlled (in US and other markets), so using a 3rd party/cloud solution is pretty well essential. |
| Should we cache? | Yes – most of your backend load will be serving cacheable assets. However, you cannot use cache timeout as a version system as each asset will time out independently. So you should version your CSS/HTML/JS so that a client gets a consistent set when you make a coordinated change. |
We now move to the last platform function, the API structure.
API
Your API will be used by your browser and potentially your customers.
| Decision | Typical design response |
| How do clients authenticate? | There are four approaches – (OAuth would be the default): – password – simple for low-end users, but does not support delegating and access control – mutual TLS – robust for high-end corporates – SAML – might be right-to-play for some corporates – OAuth2 – obtain a long-duration token that captures the authentication and authorizations and present short-duration tokens on calls. |
| Documentation? | OpenAPI for REST |
| REST? GraphQL? gRPC? | REST at Richardson Level 2 is the industry norm. You should consider GraphQL if you have rich data where clients want different and unpredictable subsets of it (it breaks caching). gRPC is a leading-edge choice for high-speed server-server APIs but is cumbersome for browsers. |
| Idempotent? | You want an Idempotent API – it makes client recovery so much simpler (just resend on timeout). For operations with side effects (such as making a purchase), you cannot use POST operations, and the PUT operations must have a client-supplied Id (e.g. the purchase order number). |
| Versioned? | Try to make your API changes backwards compatible (adding fields). However, the time will come when your old API has a mistake or contains something you no longer wish to support or has grown in complexity – at that time, create a new version and announce an end-of-life date. |
| Cache | Spend time to get cache control headers right – hours is usually good. |
| Encrypted content | API content with sensitive data (e.g. credit cards) should be encrypted at the application layer (JWE) with an asymmetric key. This is to counter DNS attacks, allow last-mile proxies, and support defense-in-depth. |
We now wrap up with some miscellaneous issues.
Other considerations – mainly operational 

These last considerations are important, but don’t relate to the hosting sections we covered above.
| Decision | Typical design response |
| What business monitoring? | You need to publish key business metrics about your system (usage rate, completion rates, backout, daily users, etc.). These should be detailed enough to track the business case projections. |
| What functional monitoring? | You need to publish and alarm on the key function metrics or the live traffic (latency, concurrent users etc.). This might be your first indicator of system failure. UI tools like Google Analytics are helpful here. |
| To use surrogate traffic? | Generate surrogate traffic (e.g. using AWS Cloudwatch) to your external API and alarm on failure. |
| Outageless deployment? | Typically, a Blue/Green upgrade is more robust than a per-service upgrade for small and new systems. This requires strong discipline in DB scheme changes so that roll-forward and rollback of schema change are tested. Don’t rewrite stored data – instead, version it. |
| A/B testing or feature toggles? | For a system with a large established base, A/B testing is a way to mitigate roll-out risks. One process is to deploy the new features in a disabled state and then enable them in a controlled manner while observing the customer impact. |
| How to bill? | You need to design a billing approach (e.g. taking payments, feeding to a corporate accounting system etc.) |
| What do operations need to see? | Provide all the metrics to ops or dev-ops staff so they can observe this system. This needs to be designed to ensure that every conceivable fault will show as an impact in a metric. |
| Fault LifeCycle | A fault has five phases – Detect, Isolate, Mitigate, Remedate, and Return. You need to practice and design each of these for your system, for each likely fault. Failover is one mitigation, but it is not a cure for all faults (e.g. express load, software defects) |
| Infrastrcuture as code | It’s 2023, do it. Your cloud gives you good tools. Without this, you cannot effectively do pre-production testing. |
| 4×9’s or 5×9’s | It’s not that hard to run 5x9s in a modern cloud, but it will impact how you design and, to a large extent, how you operate and manage the system. This is for another post. |
| User login | It’s really hard to build this well – use Google, FaceBook etc – and you customers will thank you for one less password. |
| Smoke test | You should run basic functional testing on all aspects of the system in production. This will be an aid to early fault detection, and it will help in isolating faults. |