We have stuffed up

We have all seen the stats about the impact of data breaches – personal records are worth $100 each, a $5 million average cleanup cost and an $11 trillion drain on the world economy. That’s the GDP of the 130 poorest countries on earth. As software architects, we enabled all that. We built insecure systems, we left key defences to our operations colleagues, and we offered “quick OR secure” options to our leaders. In our hubris, we put insecure systems on the Internet, declared them ‘done’, and set up our users and employers to become victims.
We should be ashamed.
Cryptographers have given us sharp tools – unbreakable encryption, irreversible MACs, and protocols that cannot be penetrated. OWASP shows us dozens of vulnerabilities in priority order. Threat modelling using STRIDE and DREAD let us quantify risk. However, applying those tools is hard, and mistakes are easy. If we individually try to apply security tools, we will make mistakes and consume ridiculous amounts of effort. Our failing as a profession is a lack of blueprints or patterns of how to build secure systems, especially for those of us with less-than-great security skills.
In a series of articles, I will look at some common scenarios and suggest best-practice solutions that take security as a prime requirement. For most attackers, Personal Data is the prize, and it’s easiest to steal when it’s not moving. So this first article is on how to protect Personal Data when stored. I will have to demolish two widely used and dangerous approaches – TDE and SQL access controls – techniques that are 15 and 50 years old and totally inadequate for today’s security threats. But first, let’s look at what you have to achieve.
What is your responsibility?
 Motivations for data protection:
Motivations for data protection:
- ethical – people trust you with their data, don’t betray that trust,
- compliance – protect data so that you pass your statutory audits and convince customers to buy your product,
- financial loss – don’t let data be stolen and then suffer class-action law suites, fines, loss of sales, and reputation loss.
As the person responsible for protecting data, they are all views of the same things – each more concrete than the one above. Based on the EU’s GDPR as the Gold Standard, three simple principles cover most of your responsibility:
- Limit storage – Limit the amount of data you store – collect just what you need for your business purpose, and destroy it when you no longer need it.
- Limit access – By default, prevent access to data and only show it to people executing that purpose in a way consistent with that purpose. Just because you need a customer’s email does not mean you need to list all customers’ emails, see 100 emails per second, or search by email.
- Be accountable – Do all this within the system you build (and regression test) – don’t put the burden on your operations colleagues, DBAs, or manual processes.
Do this, and your data storage is safe (there is more to security … later posts). Here are some counter-arguments and some Defence Against Bad Ideas.
| Argument | Defence Against Bad Ideas |
| We might need <X> in future. | If customers gave consent for X, then we can securely store the data now and build it in the future. |
| We might want to sell the data. | If they gave consent, we can store the data now and build a secure channel for our data customers. Then if the data is stolen, we won’t be the cause. |
| As a product manager, I want to hold the data indefinitely and analyse it in new ways in the future. | Do you really need their street number? Do you need to reanalyse data from 1950? 2000? Just last year? Can the historical data just be stored in aggregate? |
| As a DBA, I need access to everything. | Tell me how you are doing to use the customer’s Driver’s Licence Number? Are you immune to phishing, or social engineering? If there is some emergency, we can alter access during that emergency. |
| Don’t worry about coding, the DBAs can secure the data. | Can they automate? Can they regression test? Do they have an SDLC for the stuff they write? Are their tools capable? See Fallacies – Operations can write operations software. |
| The law requires that we hold all data for seven years. | Really? If you can show me that law, then we have the authority, and all is well. If not … |
| Ethics is for Scouts, lie through the audit, and ignore the risk. | You need a new job. Two of the greatest IT leaders of all time, Thomas Watson (Jnr and Snr) of IBM, were Boy Scouts. |
| We’ll leave that to the next iteration, quarter, or year… | (This is a polite form of the above). Ok, I’ll document the risks and give it to the lawyer/policy owner/my boss, and if they sign it, we can file that in the project risk register, and I’m OK. However, retrofitting security will be more expensive than getting it right now. |
| As <insert senior role> I will own that risk. | (This is an aggressive form of the above). Same answer as above. |
Architecture is a human task done in the real world. In an architect interview, half the questions will relate to how you handle human issues like these. A powerful architect’s argument can be, “What you ask breaks <the law/company policy / best practice>. I don’t have the authority to do that. If you can get signoff from <lawyers/policy owner/my boss>, then I’m OK to go ahead“.
Encryption is the best tool we have to control access to confidential data. This is a segue into the next section, “How NOT to use encryption“.
Don’t try this at home (or anywhere actually) 
Transparent Data Encryption (TDE) is where the database automatically encrypts the data written to disk. It uses strong cryptography (typically AES) and has a small performance impact (around 5%). What could be wrong with that?
- It’s also Transparent Data Decryption. Anyone with DB credentials gets the data decrypted.
- The encryption keys are typically obfuscated on disk (though most DBs support HSM). If you deploy or back up a TDE database in the obvious way, an attacker can steal both the encrypted data and the key and so see everything.
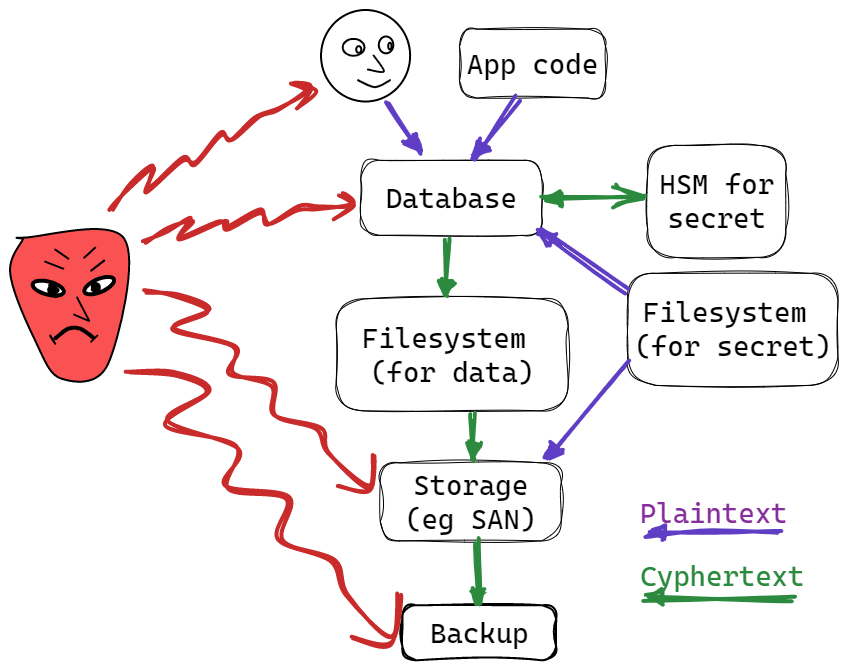
This diagram shows how TDE works. With TDE, an attacker cannot steal data from the files that hold the data.✓ If you use an HSM, they cannot steal from the SAN or backup (✓), if you don’t, they could (🗙). Admittedly these are hard exploits. But critically, TDE has zero impact on attacks on the database (stealing passwords) or users (social engineering). So let’s focus on that:
TDE has zero impact on the two easiest attack vectors.
Ok, I hear you say, “that’s better than nothing” No. It’s worse than nothing, as it gives your organisation a false sense of security, allows them to tick the ‘encrypt data‘ box and cuts off the funding for actual protection. Let’s play out the scenario between Anna Architect and Mike Manager.
Anna: I’m scheduling App Level encryption in the next iteration of our SuperSerious project.
Mike: Hold on a minute, that’s going to take a whole iteration. I had a chat with Oliver, the DBA, and he says we could just use TDE. His people can set it up for no dev effort at all. It’s always good to get a second opinion, and he is the DB expert.
Anna: I know about TDE, it is not very secure, attackers can still hack passwords, and that’s how data is usually stolen.
Mike. Does it meet the encryption requirement that MegaCustomer asked for in their RFP? Is it industry best practice?
Anna: Yes, and sort of – it is widely used.
Mike: So you’re telling me that it’s recommended by our database vendor, and it complies with MegaCustomer, and our DB expert gives it the tick, and it’s widely used, but it’s not good enough for us? You want to spend another hundred days playing with code when Oliver can do this by just ticking a box on the DB console?
Anna: Yes, even Microsoft is very careful to claim very little for TDE.
Mike: I need to talk to your boss, this gold plating has to stop.
I know it sounds dramatic, but TDE has been a gift to criminals and one of the worst security options ever invented. I will show how to use encryption wisely later on, but first let’s demolish another Bad Idea, SQL access controls.
Don’t let humans access the database
 Data is valuable not just to your attackers but to your organisation. You can use it for billing, reports, sales leads, product uptake, debugging, audits, cross-matching, reconciliation, inventory control … So there is an argument to let humans – DBAs, report authors, dev-ops, the billing team, customer support, and so on access your production database (or a read replica). These people have a legitimate purpose for accessing some data in some way. But I’ll show that SQL access to production data is a Bad Idea, as it means you cannot take accountability for your data protection.
Data is valuable not just to your attackers but to your organisation. You can use it for billing, reports, sales leads, product uptake, debugging, audits, cross-matching, reconciliation, inventory control … So there is an argument to let humans – DBAs, report authors, dev-ops, the billing team, customer support, and so on access your production database (or a read replica). These people have a legitimate purpose for accessing some data in some way. But I’ll show that SQL access to production data is a Bad Idea, as it means you cannot take accountability for your data protection.
No human WRITE access to the DB is usually undisputed. This lets you (through your code) take accountability for the “Store/Use for Purpose” and “Data Destruction” principles. As the WRITE credentials are only presented by your software, all WRITE credentials can use strong authentication, such as mutual TLS or strong passwords (stored in a Vault, such as HashiCorp Vault or Secrets Manager). It’s relatively easy to continuously audit who has DB WRITE access, and you should do so from your code (see Fallacies about Operations for why). Remember, a defence without a defender is an attack point.
READ access is tougher. If you allow SQL READ of Personal Data by any human, it is impossible to meet the data protection principles. Two reasons:
- The design of SQL SELECT and GRANT means that if you give access to a data set, you give unrestricted access to all instances at a high rate. “Data set” might be all the data in a table or column, or defined by row-level security. For example, a support person might need to look up by phone number, so
SELECT Name from Customer where Phone=’555123456789′; is a query for a legitimate purpose, but
SELECT Name from Customer where Phone!=’555123456789′; takes your customer list, and
SELECT Phone from Customer where Name='<estranged spouse>’; is a crime. - Once SQL outputs the dataset, then you cannot control it in any way. You cannot check if it’s used for the purpose, held securely, or when it’s destroyed. Yes, you can have security policies and staff training, and so did every company that had data stolen. Humans make errors, and in cyber security, seemingly small errors can have enormous consequences.
In a threat model, any SQL SELECT access should be considered to take a copy of the database. Using a DREAD assessment, each of DR_AD rates as 3, with E at 2-3 depending on your exfiltration controls, with an overall score of 14 to 15 out of 15. This means High Risk. But you say – “We have 2FA on the DB access“. Well done, that effectively removes password scans or reuse attacks on the DB itself, but do you have 2FA on the data that the person downloaded? And are your people immune to social engineering? Probably not.
Another “Ah ha!” I hear you say. We can give people DB access to data that is not Personal Data! If you don’t care about that data, then maybe. In most systems, some tables are not Personal Data, such as the Company table. As a developer, you can segregate Personal and General tables (say by tablespace) and then code an audit control on the Personal table as described above. However, that probably won’t get you too far.
General data is pretty bland, and your company will probably want more – they will want data related to how your products are bought or used, for example, the City for a sales report. If you have a denormalised database, then the personal and non-personal data are likely to be mixed in one table or column. For example ORDER.ADDRESS holds “15 Big Street, Littleton” – Littleton does not identify a person, but 15 Big Street does. If that’s the case, it pretty well puts an end to allowing human access to the database – the only data that you can safely reveal is too bland to be interesting to your company.
You could assist by teaching your code to write the Order.Address (as normal) and also write (but never read) PublicOrder.Address which omits the street information. You’re effectively taking the first step toward building your own data warehouse (see Data Extraction from microservice architectures), and that’s not going to end well.
In summary, this leads to the conclusion:
Do not allow humans to have DB access to Personal Data, as you cannot comply with Personal Data legislation.
or its corollary:
If any human (including DBA and dev-ops) has DB access to read data it will be stolen.
Your organisation will be drawn to your database like bees to a honey pot, my suggestion is to provide a better and safer honey pot, in a data warehouse that excludes Personal Data. So having swallowed two “don’t do this“, now let’s move to some “do this“.
Application level encryption
 The second best protection for Personal Data is application-level encryption. This is where you:
The second best protection for Personal Data is application-level encryption. This is where you:
- write code that encrypts the Personal Data and writes that to your data store, and decrypts it when read,
- use a symmetric key that you get from an OTS key Vault (or HSM),
- provide a warehouse (of some type) for data reporting, and that warehouse contains no Personal Data (see ETL),
- code the legitimate cases where Personal Data can be accessed, and log that access,
- limit the rate of data presentation to that required by legitimate usage (eg Customer Support is limited to seeing less than 50 Personal Records per hour and 200 per day).
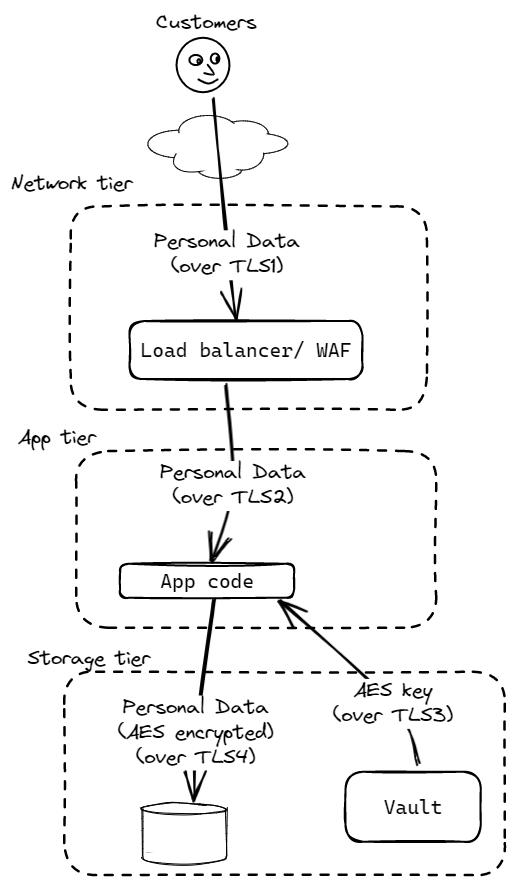 |
 |
| Vault version (OK for most systems) | HSM version (Health, Credit cards, Government, millions of records ) |
The Vault version stores the encryption key (preferably) in your cloud’s Vault (AWS Secrets Manager, or Azure Key Vault) or on-prem HashiCorp Vault (good product, but weaker security without an HSM). As the keys leave the Vault and exist in memory, they can be extracted with some effort. That’s not good enough for health records, government records, or if you store millions of personal records. Then you need to step up to the HSM version- it is costly (AWS pricing puts it at $50k per annum for the four HSMs you will need).
Your Personal Data now has a LOT of protection:
- No person should have credentials for both the DB and the Vault/HSM – this is called Separation of Duties (SOD). This makes all attacks much harder – to steal data, you need to steal two credentials that have no common storage or person. This cuts off accidental exposure, theft by staff, and external attacks.
- The DB, the underlying file system, and the backups are no longer attack vectors.
- You control the rate at that data can be exfiltrated, effectively preventing humans from creating unauthorised DB copies.
Just as an inside, I put some of the data-in-flight protections in the example diagrams. I just could not bring myself to present diagrams without that, but that’s the subject for future posts. What is relevant to this post is the tiering of the data away from the Internet – you need to make it very hard for an attacker to reach your DB. Traditional firewalls or your cloud’s security model (eg AWS Security groups or Azure NSG) are the best way of achieving this.
But what about …
- What cipher do I use? This is an article in itself, but to be safe use: AES128-GCM with a random 12-byte nonce/IV and 16-byte tag.
- How do I make the keys? Manually use your Vault to generate the first key, and give it a useful name (eg personal_2023-01). Periodically (say monthly) roll the key by creating the next in the pattern, (eg personal_2023-02). Do this programmatically, or manually with programmatic verification. Monthly key roll means your code and process are BAU and tested – yearly can turn into a drama.
- How do I encrypt the data?
- Periodically (say hourly) – Read the latest key from the Vault (ie personal_2023-02), you might have to scan if your Vault does not support listing.
- Generate a new crypto-strength random IV for each encryption using your language’s crypto libraries (this is super-critical for GCM).
- Use your language’s crypto libraries to do the encryption – PHP, Node, Java. (Note: the Java implementation adds the tag at the end of the ciphertext).
- Base64 encode the concatenated ciphertext, tag and IV and wrap them and the key name in a CryptoBlob string:
personal_2023-01::wzrpke4+wglkaGK+nLb1fbEzt/ikDOc6CFc= - Store that CryptoBlob in the DB. It will be a bit longer than the plaintext (133% plus about 50 bytes).
- How do I decrypt the data?
- Pull the CryptoBlob apart, based on the known length of the IV and tag.
- Decrypt as above, using the key, IV and tag from the CryptoBlob.
- Handle the decryption exception by shutting your system down. If the decrypt fails your code is wrong, the key Vault is compromised or the DB is corrupted. This is bad and will require expert intervention to get back online. The good thing about AE cyphers (like GCM) is that you know it’s been compromised.
- Isn’t all that crypto slow? No – about 2us to encrypt 10kB on modern CPUs with the AES instruction set
- Row or column encryption? If you use a Key-Value storage model, then just encrypt the whole value. If you have a more normalised model, then encrypt each column holding Personal Data. However, it’s pointless having distinct columns for each Personal datum, just put them together in JSON encoding.
- Do I have to rekey? If you get a key compromised (most likely by a disgruntled employee), then your first step is key roll. Then you should rekey -just read and write each DB record using the code you already have, while the system is running. You need to throttle to not DOS the DB – you’d be looking at two days for a million records. You will probably never use that code, so it must be in your regression suite if you want it to work when the poo hits the fan.
- Can I reuse keys? Using the same key for all your Personal Data stored in one DB is OK, beyond that a different key for each purpose. If your service is SaaS and you have large customers, you should consider a key per customer – it’s a simple way to avoid cross-customer data contamination.
- But my primary DB key is Personal Data? Don’t do this, always use surrogate primary keys, and never leak them.
- How do I report? Read this.
- What does GCM stand for? Remember if you try to say his name, Évariste Galois was French, a boy who met a sticky end.
How do I search on Personal Data fields?
 I led above with “encryption is the second best way to protect data“, let’s move on to the best way – MACing.
I led above with “encryption is the second best way to protect data“, let’s move on to the best way – MACing.
It’s likely that your valid purposes for Personal Data will include some type of search. Limit this to prevent spying on neighbours, spouses, rivals … or to thwart compromised credentials or social engineering attacks. Never build functions relating to Personal Data just because it’s good UX, or it might come in handy, or because the tech stack supports it … only build functions that have a clear link to a valid purpose. This is just part of “reducing the attack surface“. It’s also the strength of coded access – code is a precise additive process – you start with no function and add it as required. In contrast, DB access is subtractive – you start with full access and use blunt tools to block off access when you see a threat.
Consider that you need to search by passport number, and that is an indexed column. The best approach is MAC searching.:
- Create a 64-byte HMAC key in your Vault.
- Create an HMAC_SHA256 of the data concatenated with the table/column name, using your language’s crypto library, and Base64 encode it. The result will be 44 bytes, which you can store in your indexed column. (The column name is to prevent an attacker from injecting data in one column to find data in another.)
- To search for the passport number, create the HMAC(s) and search for that.
- Roll the key every (say) year, and include multiple HMACs in the WHERE clause. Align the key roll period to your data retention period to prevent excess keys – for example, 2-year retention and annual roll means comparing two keys.
In some circumstances, an attacker with access to the database is could mount a frequency or known-plaintext attack, so protecting access to the DB is still important. However, it’s hard to leak a lot of Personal Data like that. Do not:
- worry about performance – HMAC_SHA256 takes about 0.5us on 20-byte typical payloads,
- worry about HMAC collisions – probability is 4 x 10-60 (how would you would write a test for that?),
- use encryption without an IV – less secure and you will have problems explaining it to auditors,
- use a hash (eg SHA2) – you can force all Australian passport numbers for about $50 of AWS GPU,
- join on hashed data (ie for both name and passport number) – instead, produce one column with the joined data.
Application-level data destruction
 Data must be destroyed when there is no longer a purpose to hold it. This drops your dreAd score and legal liability. You need a person’s driver’s licence as part of your KYC process, but do you need to store it? or do you just need to store that you’ve sighted a license ending …1734? Do you need Personal Data from people who have not used your service for a year? You need to think long and hard about this, but whatever the answer, the result is that you will destroy data at the same rate as you create it.
Data must be destroyed when there is no longer a purpose to hold it. This drops your dreAd score and legal liability. You need a person’s driver’s licence as part of your KYC process, but do you need to store it? or do you just need to store that you’ve sighted a license ending …1734? Do you need Personal Data from people who have not used your service for a year? You need to think long and hard about this, but whatever the answer, the result is that you will destroy data at the same rate as you create it.
Some efficient approaches to this:
- keep monthly tables and DROP the current-minus-N table at the end of each month,
- rate-controlled DELETE statements,
- set Time-To-Live value for Cassandra, Cosmos or Dynamo data.
It’s NOT, “pass it to the DBAs and see if they can figure it out“, and it’s not running your load tests with data destruction disabled.
What about COTS?
This US Government article gives a thorough analysis of the high risks associated with COTS:
- Naivety – COTS looks simple – however, each deployment needs complex security responses, up-front and ongoing.
- Downplay security – COTS is often sold to the C-suite on business value, so by the time security questions are asked, the vendor knows they don’t have to answer – both vendor and purchaser are seeing security as another project delay. You can be certain the contract will ensure that all liability lies with the purchaser.
- Generic – COTS is generic, so it probably won’t match your Personal Data obligations. COTS often presents ‘secure-vs-convenient‘ or ‘secure-vs-functional‘ tradeoffs or an eco-system of SOUP. That’s battle security never wins. Until the breach of course.
- Target – Attackers love COTS, as it maximizes the return for discovering an attack.
I don’t have answers to this. I cannot work out how to stop an organization from having their customer list in Excel with the Phone column hidden and then putting it on a shared drive. I think SaaS is inherently safer than COTS – the vendor has greater secure hosting skills, more to lose on a breach, and more contract accountability. But, I suspect nothing will change much until severe fines and C-suite sackings become the norm for data breaches.
In conclusion
Follow these rules and your risk of Personal Data theft is much reduced, your statutory compliance will be good, and you’ll be able to convince your customer’s their data is well managed:
- Store your passwords and crypto secrets in a Vault, preferably from your cloud host. If you have high risk, use an HSM.
- Host the Vault/HSM and Database in a tier with no Internet access and with TLS connection.
- Prevent human access to the DB, and code alerts on a violation.
- Use strong authentication for your application’s access to the DB.
- Use application-level encryption for all Personal Data, and HMAC searching.
- Only write code to process Personal Data that supports the defined purpose and read rates- no emblements.
- Only store the minimal data and delete it when there is no longer a definite purpose.
- Build a warehouse for your business searches, and have no Personal Data in there.
- Build security starting in your first iteration.
Like the two people being chased by a bear – you don’t need to outrun the bear.