This is an article about operating your software in production, and how you can get a better result if you don’t make incorrect assumptions about operations. Back in 1994, Peter Deutsch (and co) penned the Fallacies of Distributed Computing. You must read this – it’s foundationally important as all systems today are distributed because of this Internet thing, which was really not such a big deal in 1994.

 Operating production software is much more complex than when Larry and Sergey built Google Mark 1 twenty-five years ago, compared to the world’s largest data centre that Mark built in 2022.
Operating production software is much more complex than when Larry and Sergey built Google Mark 1 twenty-five years ago, compared to the world’s largest data centre that Mark built in 2022.
When we design software, we have to make assumptions about how it is deployed and administered. If those assumptions are wrong, the system will (eventually) fail in some way we care about – security, performance, reliability, scalability… In this article, I outline six Fallacies about Operations – invalid assumptions software developers often make about operations. Before I get going, I want to pay respect to my colleagues in operations and emphasise that this is not an attack or critique of how they work. I worked in operations for ten years and have some insight into its complexity. But how operations works is different to how software development works, and fallacies exist because we, on the software side, too often don’t understand that difference. We cannot design systems that work and keep working without that understanding. (Note the emphasis on keep working.)
- Operations test just like developers do.
- When something breaks, operations can identify and fix it.
- Infrastructure outages are not the software’s fault.
- If it works when first deployed, it will keep working.
- We understand the production load and capacity.
- Operations can build operations software.
Six Fallacies of Operations
1. Operations test just like developers do
Ideally, any change on an operational system would go through the same process that software changes do:
- The change will be implemented, reviewed and tested (function, load, security …) on a pre-production system.
- The regression test suite will be updated.
- It will be rolled into production via tooling.
- If it fails, there will be a tested rollback.
- There will be monitoring and logging in production.
That’s the end goal of Infrastructure-as-Code (IaC), described in documents like AWS DevOps Best Practice. However, there are a lot of barriers to getting there. Firstly, automation is a huge change in mindset, one that we on the software side did around ten years back. We let declarative tools, like Maven and Jenkins, automate the build and test of our software. Ask yourself, could a member of a modern dev team compile their code by hand using javac anymore? It took around ten years to go from hand-crafted batch scripts for building, through ant on to model-based builds. The operations equivalent to Maven would be Terraform or CloudFormation, but Terraform’s first release was ten years after Maven’s. There still appear to be no tools for regression testing infrastructure today, say the equivalent of JUnit or Gatling.
2. When something breaks, operations can identify and fix it
Production stacks are hierarchies, so you can draw a diagram where the arrows all point down. It’s not strictly true, but close enough. Some parts of the stack are fault-tolerant, so a single failure produces an alarm but does not interrupt its service. This is common in the lower part of the stack, like power supplies or disks in SANs. But it’s not true further up the stack for databases, queues, and most network stuff.  If a router occasionally drops packets on HTTP responses, then that probably won’t be detected by a network layer function. It will have the effect of causing TCP retries or maybe occasional TLS connection failures. In turn, that causes long database queries, or excessive message queue rereads, or retrying messages between microservices, or … In an ideal world, the network layer would recognise its errors and produce an alarm that says the SYD-53-A router is faulty. The ops team would then just block that router, and SYD-53-B would takeover that traffic and all would be good. And sometimes, that actually does happen. But too often, the impacts of the fault spread through the system and produce unexpected and complex responses. Let’s look at a realistic example.
If a router occasionally drops packets on HTTP responses, then that probably won’t be detected by a network layer function. It will have the effect of causing TCP retries or maybe occasional TLS connection failures. In turn, that causes long database queries, or excessive message queue rereads, or retrying messages between microservices, or … In an ideal world, the network layer would recognise its errors and produce an alarm that says the SYD-53-A router is faulty. The ops team would then just block that router, and SYD-53-B would takeover that traffic and all would be good. And sometimes, that actually does happen. But too often, the impacts of the fault spread through the system and produce unexpected and complex responses. Let’s look at a realistic example.
 There are a few lessons here:
There are a few lessons here:
- There is no obvious link between the root cause (the dodgy router) and the reported defects (call centre queue length).
- There are multiple errors (two software defects and a hardware defect). Fixing either the SW or HW errors means there is no customer impact. This is the “Swiss Cheese Model“.
- There are multiple ‘Wise Monkeys’ who speak no evil and just pass the defect onto their client to manage.
- The system users are the last client and will find any errors that are not corrected within the system.
- There are positive feedback paths that compound the error (‘More help calls‘, ‘Increased Refunds‘), often it’s retries by the system or the customers.
- Some of the effects cannot be ‘just fixed’. Fixing the router does not make missing refunds happen, nor the fraud investigation go away.
Let’s trace a scenario when the Call Centre initiates a support call reporting slow lookups.
- Operations ask the DBA to check the DB, the ‘usual suspect’. DBA says response times are slightly high. The complex call centre queries are actually very slow, but their statistic is buried in the website calls, which are hardly impacted. The DBA reports the DB is good.
- Someone notices that the application error log rates have increased significantly, especially for Queue-Write. The queue is checked, and it is OK.
- The bank connection log shows a doubling of rejected transactions. This happened last December when the bank had issues, so operations call the bank. And all is well.
- Call centre queue is long and their bonus is in jeopardy, so they call the CEO. She gets on the phone and asks for a report, so dev-ops starts working on that. Surprisingly, this does not fix the fault.
- After an hour, the operations manager calls for a blue/green failover. Sadly, that does not work (the faulty router is on both stripes).
- The finger points at last night’s R7.32 software update. This is rolled back. Disappointingly, the problem remains.
- The finger points back at the hosting. So the operations manager orders a DR failover, which causes a 15-minute outage.
- The call centre queue is now even longer, as customers complain about the failover outage. However, logging shows the errors are down to normal. So, the operation manager stares down the call centre manager, saying it will come good. Which it does.
- Eventually, the router vendor dumps some SNMP tables, and finds the fault.
Sadly, it’s not over. Teams now have to troll through the logs and find and fix the 683 customers that missed their refunds. This takes three weeks. The COO writes a report to their bank explaining why they should still be allowed to process credit card payments.
One simple command into one router could also have fixed the whole problem. However, due to the system’s complexity, no one could know that, so it was not done. Doing the failover earlier would have solved this problem, but not the issue last December. You really cannot fault the actions of anyone here (except maybe the blue/green failover should have happened earlier). So, moving up a bit, the fallacy remains:
- For a whole class of faults, operations cannot easily identify a root cause.
- Without knowing that, there is no simple repair, and so service interruption times can blow out.
- It can take a very long time to debug what is wrong, or what to do to get the system working again.
To counter this, your application needs to alert then things are wrong, compensate for any errors that are caused, and backoff the faulty item till it is fixed. Nygard goes into a bit of detail about this.
3. Infrastructure outages are not the software’s fault
Pretty well any outage post-mortem will lay blame at the feet of the software. With modern CD/CI/Test processes, the functional software itself is rarely the root cause of a fault. However, the software will have a deeper fault, as one of its design premises is a fantasy. It assumes that the hosting stack is reliable.

 Pre 1961, the Volkswagen had no fuel gauge. You swapped over to the reserve tank when you heard the engine spluttering. Usually, it worked. That’s the VW DR switch in the photo on the left. However, not all spluttering engines were due to low fuel, so if it kept spluttering, you had to use the advanced analytics, which was the dipstick on the right. Sadly, that’s where a lot of production software is these days. If we hear the customers whinging, then operations eventually flick the DR switch. As we saw in the previous fallacy, it’s really hard for operations to identify many of the faults in the hosting stack. That’s why we failover, it usually works without operations understanding what is at fault. You must have a standby (DR, pilot-light, or co-processing) site if your system needs anything above 99% monthly availability or less than 8 hours MTTR.
Pre 1961, the Volkswagen had no fuel gauge. You swapped over to the reserve tank when you heard the engine spluttering. Usually, it worked. That’s the VW DR switch in the photo on the left. However, not all spluttering engines were due to low fuel, so if it kept spluttering, you had to use the advanced analytics, which was the dipstick on the right. Sadly, that’s where a lot of production software is these days. If we hear the customers whinging, then operations eventually flick the DR switch. As we saw in the previous fallacy, it’s really hard for operations to identify many of the faults in the hosting stack. That’s why we failover, it usually works without operations understanding what is at fault. You must have a standby (DR, pilot-light, or co-processing) site if your system needs anything above 99% monthly availability or less than 8 hours MTTR.
As a bare minimum, your standby host must:
- have an up-to-date DB (few minutes of replication lag),
- have real (or very realistic) traffic flowing through it end-end and out to the external systems at all times,
- be activated by operations with one simple action and will be working within 10 minutes,
- be part of your application regression test.
If you cannot do that, then it truly is the software’s fault. If you don’t deliver on any of these items, then operations will be hesitant to flick the DR switch. If a senior operations person has to make the failover decision, or if the DBA is involved, or the network engineer has to swap DNS entries, or it has not been tested since last July, then you will have extended the outage – maybe by an hour. However, DR does not solve all problems. External systems can be down, or your front end might be down, or your mobile app might be faulty, or … Why is this the software’s fault? The software, the part we build, is the only part of the system that can realistically do these things:
- detect business-level failures,
- see all the platform issues,
- know what it needs from the platform for availability, latency, and throughput,
- have enough sophistication to detect errors and act on them (say, by shutting down a link, retrying, or rolling back),
- organizationally do it – the DB vendor, queue vendor, or VM provider just won’t do the stuff you need done.
This also applies to front-end failures, such as a load balancer, internet connections, WAF, your browser code or mobile app. It’s not OK for your software to sit there with a smug smile on its face, processing one operation per second during your busy period. Telco switches take this to an extreme level, around 90% of the AXE software was dedicated to monitoring the hardware, network and business function. And such switches could deliver 99.9999% availability.
So, if the network engineer misconfigures a firewall and blocks both your bank connections, or your software lets refunds timeout in a dead-letter queue, then that’s your problem. You could blame the network engineer, or the operations person who should monitor the queue, or the stupid router that let you block both connections, or the ops team for not monitoring the logs, or … yeh, whine on. You know stuff breaks, you know it’s not monitored, and you know that it’s not regression tested. So, it is your fault if you assume otherwise.
4. If it works when first deployed, it will keep working
We are moving past equipment faults here and considering intentional changes to the stack. We want our stacks to get better over time – cheaper, faster, more secure … This means operations need to change stuff. We might also have multiple applications running on the stack (it’s the norm for on-prem), and the isolation of those apps is imperfect. So, adding or changing an application that we don’t even know about can break our app. Obviously, our operations colleagues try to do their best to keep it all working.
- There was no strong specification of the stack when we deployed the first time. We just tested and watched it work on the stack of the time.
- There is scant operational regression testing that validates the post-behaviour of an infrastructural change matches the pre-behaviour.
- The software regression rarely exercises the fullness of platform behaviours. So when we see that, say, DB backup does not impact the app, we usually don’t add a test of that to our regression.
- If you aren’t doing Infrastructure-as-Code, you probably don’t have a pre-production environment that matches your production environment.
You now are warned, you know stack changes will happen, you know some of them will change the application behaviour in unexpected ways. So, design your monitoring, logging checking and compensations to run all the time – not just at app startup, nor software upgrade.
5. We understand the production load and capacity
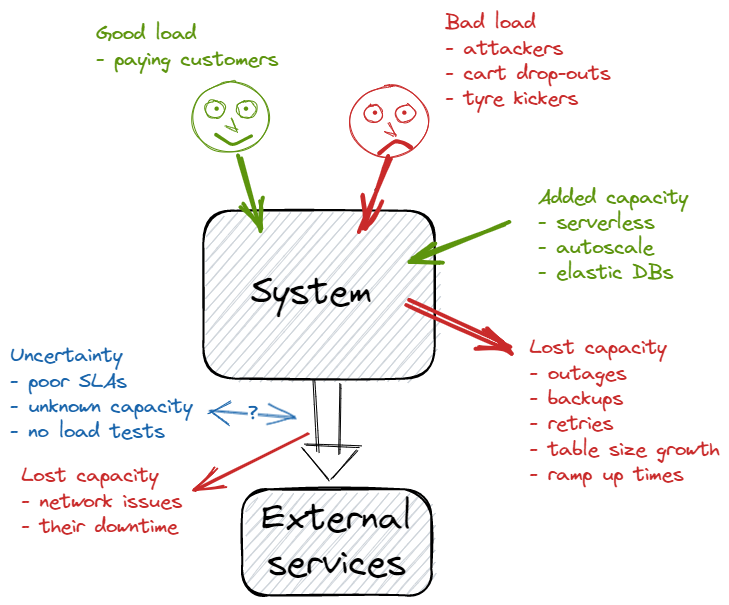
We ask the product managers the growth numbers in their business cases, and we track the organic growth. But we still cannot understand the load from Black Fridays, global political or weather events, or attackers. To counter that, we could (should) build horizontal auto-scale, or burst capacity on serverless, or sharding. If we rely on back-end services (payment providers, user authentication, KYC services, fulfilment), these can have reduced capacity due to their own issues.
All considered, our systems can still get overloaded (especially vertically scaled on-prem deployments). We need to accept that:
- input demand can exceed our server capacity in the short term
- it takes a finite time to ramp up capacity – minutes for some tech, weeks for others
- we are never sure of our back-end capacity, and we can lose its capacity without notice.
We need to design systems where it’s OK if the instantaneous (and maybe the long-term load) exceeds the system’s capacity.
6. Operations can build operations software
It’s easy for us to build a semi-operable system and then assume (or ask) our operations colleagues to build the bits we left out. Common omissions would be:
- reporting
- failover
- building consoles
- data migration
- building management reports
- managing links to service providers
- PII management (disclosure, right-to-forget…).
Because of history and necessity, most system administrators have a good grasp of bash, PowerShell and SQL, and increasingly other scripting languages like Python, Ruby or Groovy. If you have specialised programmable systems or appliances, they will also have those skills, such as F5 iRules or SalesForce DX. Invariably operations languages are scripted (so that a compile/build environment is not needed) and typically late-linked (so that library management is in the platform, not the code). The appeal of operations-built software is time-to-market and domain knowledge. It’s pretty easy for a person who knows the six things you need to do for a failover to write a script that does that. It’s fast as they are the domain expert, and the next failover will be more accurate and faster. So, what could be wrong with that, it’s just scripts?
- No code review, design documentation, or user documentation.
- No regression testing (and the ops code may read your DB tables or log entries, and so can break when you refactor your DB or log messages)
- No gated source control, CD/CI or release process.
- Poor security (credentials in disk files, for example).
- No one to maintain it when the author is on leave/resigns.
- Tendency to feature creep (5000-line bash files).
- The author probably has a real job that suffers.
Note that by necessity, these things don’t have to go wrong. Operations could build a strong code development capability, but then the advantages of operations software tend to evaporate. The things that make operations-built software fast to build are omitting the value-added steps. Good practice is to include all the software in the delivery, including the operations tooling, the monitoring, the functional code, and preferably the IaC. All are delivered through the same SDLC, using your operations colleagues as domain experts.
In conclusion
We live and design in an imperfect world. Stuff breaks, people make mistakes, and criminals attack. Often a junior engineer will ask me:
“Is it OK if I do <insert shortcut>, I don’t think that <insert problem> will happen“.
My response is this.
“If you cross a busy road with your eyes shut, then you will get hit by a car. Just because you cannot predict which car will hit you does not mean you won’t get hit. So no, go to the traffic lights and cross there.”.
Our customers and employers trust us to get stuff right, not to look surprised when it goes wrong.